视频聚合搜索 - 壹搜网为您找到"
Pytorch 介绍
"相关结果

【深度学习算法全解析】从CNN、RNN到Transformer、GNN,主流模型原理+结构+应用场景一网打尽!零基础也能看懂的硬核干货,附对比图+学习路线!
视频资料+1v1技术指导+学习路线图+程序员转行AI 关助我的微-信【服务号】➤咕泡AI 暗号:977 获取 另外还有系统课程/学术论文辅导/Kaggle组队/大厂1v1就业辅导 觉得视频对你有帮助的小伙伴 记得三连加关注!
www.bilibili.com

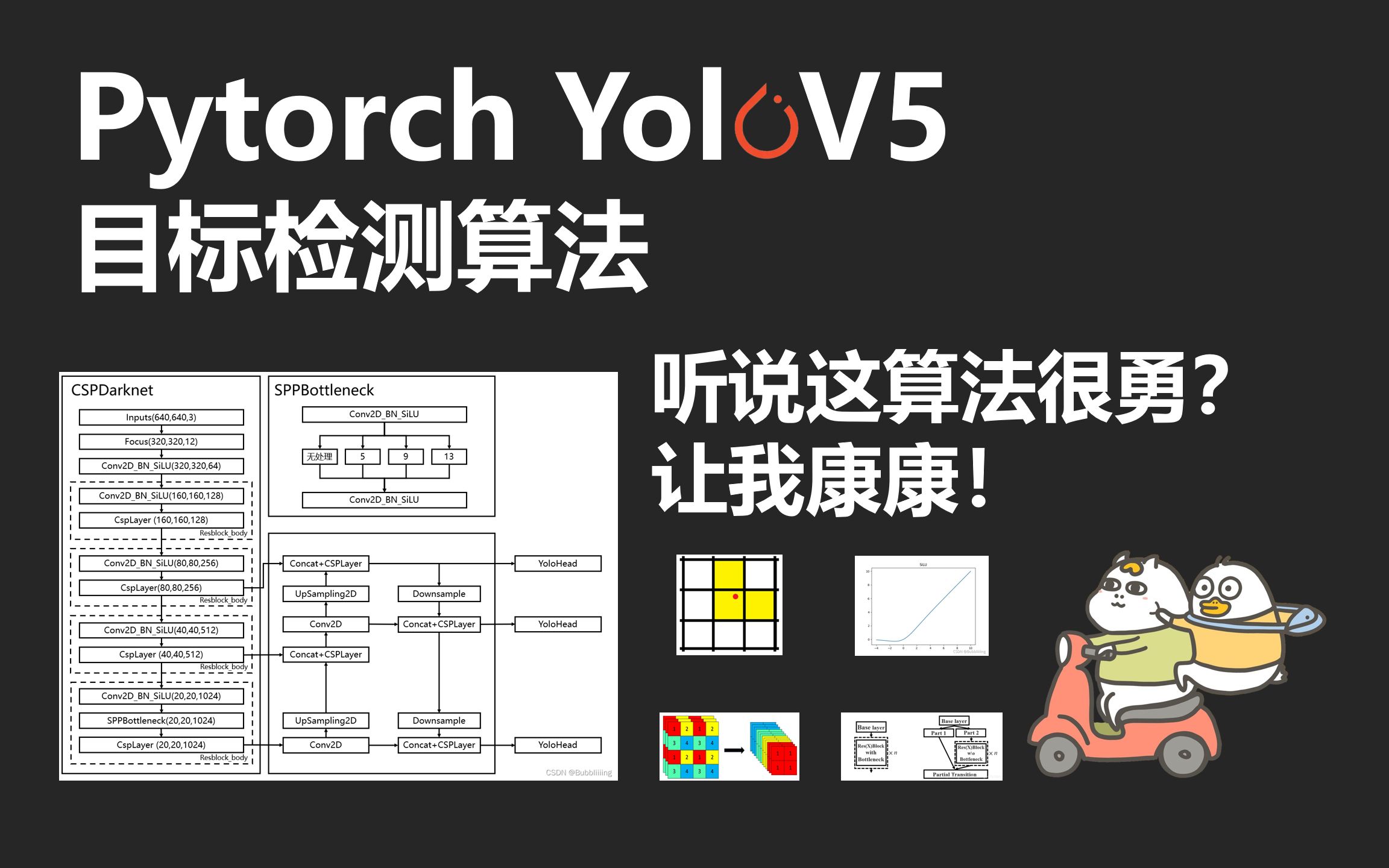
Pytorch 搭建自己的YoloV5目标检测平台(Bubbliiiing 源码详解 训练 ...
YoloV5是紧接着YoloV4提出的目标检测算法,当时觉得V5改进不大没有去学习,随着V5的不断更新,效果越来越好,最终还是决定努力学习一下,不能落后了。 YoloV5相比于YoloV4主要还是网络结构与正样本匹配方式上的改进,同时YoloV5提供了多个不同尺寸的模型,满足各个领域的要求,对于工程学习而言也非常有意义。本视频复现的是YoloV5的第五版。 博客地址:https://blog.csdn.net/weixin_44791964/article/details/121626848 GIthub地址:https://github.com/bubbliiiing/yolov5-pytorch
www.bilibili.com


Pytorch环境安装【小学生都会的的Pytorch】(2023版教程)
2023年到啦,这是新一期的pytorch环境搭建教学,包含了30系列中cuda, cudnn的安装 使用了软件版本为: Anaconda3-2022.10-Windows-x86_64,pycharm-community-2022.3 cuda_11.6.0_511.23_windows,cudnn-windows-x86_64-8.7.0.84_cuda11-archive 相比之前的教程,本教程更适合于30系列的显卡(毕竟30系列装老版本cuda老是报错啊)。。 本次教程所有资料已经打包好,记得给个
www.bilibili.com


中英 • 基于人类反馈的强化学习:数学推导与PyTorch代码解析|RHLF|...
在本视频中,我将讲解基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),这是一种用于对齐像ChatGPT等模型的技术。我将从语言模型的工作原理和AI对齐的概念开始介绍。在第二部分,我将从基本原理推导策略梯度优化算法(Policy Gradient Optimization),并解释梯度计算中的问题。我将描述如何通过引入基线来减, 视频播放量 142、弹幕量 0、点赞数 8、投硬币枚数 4、收藏人数 10、转发人数 1, 视频作者 Mindofuture, 作者简介 日更|科学,人工智能,计算机,经济人文哲学知识分享,请优先使用关键字在主页搜索稿件 wx: mindofuture,相关视频:中英 • 从零开始编写Transformer模型,包含完整解释、训练和推理|Umar Jamil,中英 • Flash Attention:基于 Triton (Python) 从第一性原理推导和编码|Umar Jamil,从零开始用 PyTorch 编写 LLaMA 2 模型|Umar Jamil,【康奈尔大学 • 中英】数字逻辑与计算机组成 ECE 2300 cornell|Digital Logic and Computer Organization,MIT《行为经济学|MIT 14.13 Psychology and Economics, Spring 2020》中英字幕(豆包翻译,中英 • 神经技术:过去、现在和未来 | Forest Neurotech|脑机接口|神经科学|认知科学|智能|神经元|大脑|AGI,[自动字幕][2025新版] 卡内基梅隆大学 11-785:深度学习导论,中英 • C++和C语言ACCU大会2024|人工智能|架构|函数编程|静态分析|安全|编译器|开发者|垃圾回收|链接器|代码生成|cmake,【经济学速成 • 中英】Economics | CrashCourse,博弈论|双寡头垄断竞争 | 微观经济学
www.bilibili.com


60分钟Pytorch从入门到精通【第四期】!对零基础小白超友好的Pytorch教程~和学姐一起组队共学吧~
第四期来啦!这期继续上手编写代码!farfar学姐用动画分享自己的机器学习知识,欢迎一起组队学习,用AI提升科研效率~👏
www.bilibili.com